
6 things to know before autoscaling your Kubernetes cluster
Have you decided to stop wasting money on nodes you don’t use? Do you want a flexible infrastructure to respond to real-time demand without manually setting your nodes? That is where Kubernetes autoscaler comes into the scene.
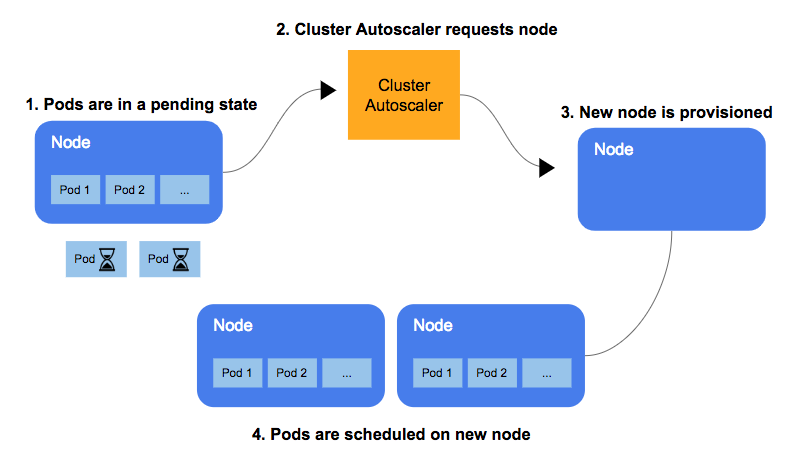
What is cluster autoscaler
When a pod begs requests Kubernetes to be scheduled, Kubernetes checks whether it has nodes with enough resources to accommodate the pod (based on the resources requested by the sum of all its current pods); in case it doesn’t, lower priority pods can be evicted, to accommodate the new pods.
If it can’t find a place for the new pod, it marks the pod in a Pending state and start the process to spin up a new node; the new node is provisioned and then can receive the new pods.
Here, I’ll describe six essential things to remember when preparing your cluster to scale smoothly, so you can go to bed without worrying about being paged at 3 am.
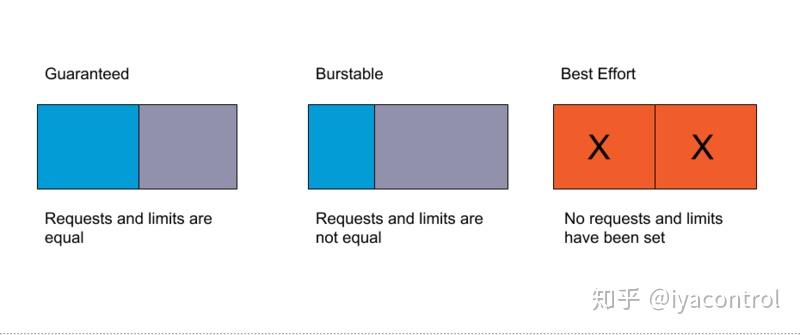
- Resources definition
Kubernetes likes to know about their workload beforehand; pods with neither requests nor limits defined run in the QoS(Quality of Service) class
BestEffort,which puts them on the top of the eviction list. Make sure you have your pods with adequate quality of service, and please, don’t let your pods without their resources defined; autoscaler won’t get along with them well. You can use a policy engine like Kyverno or OPA to enforce it.
-
Watch out for Pods that Need Longer Periods for Graceful Shutdown: When dealing with these slow dudes, you have to make sure your autoscaler is patient and gives these pods the time they need to shut down gracefully; this can lead to slower scaling and will make you reconsider or rearchitect how those pods work.
-
Monitor properly Keep an eye on the speed at which your nodes are spinning up, how long your pods are scheduled end-to-end, the number of failed schedulings, and failures to spin up nodes. You don’t want those things to go unnoticed.
-
Balance of Nodes in Different AZs Don’t let your nodes spin on a single AZ; make sure to have some auto-balancing in place,
clusterautoscalerhas a flag exactly for this purpose. Make sure you don’t have any conflicts operations; for example, AWS has its own AZ Rebalancer and when operating along with Kubernetes autoscaler it can have undesired effects. -
Select the best expansion strategy With the
--expanderflag, you can select among a few different strategies to select the node group to expand when needing to scale,least-wasteis a good starting point, but you can also select based onpriceorpriority. -
Do you need a faster scale-up? Sometimes the time to spin up a new node can take a few minutes, which might not be optimal for some scenarios; you can achieve that by overprovisioning, basically running dummy pods with low priority, they will be evicted in case new pods with higher priority need to be scheduled, and the new pause containers will force the cluster to scale up!
Now, you can grab a coffee, open your cluster dashboard and look at all the magic of scheduling and scaling.